


Muchas promesas de buen precio se relacionan con los algoritmos de aprendizaje automático (machine learning) o autoaprendizaje (self-learning). Los macrodatos (big data) y una elevada potencia informática son requeridos para ver los primeros frutos. En aquellas aplicaciones con sensores en sistemas de mantenimiento predictivo, un microcontrolador basado en ARM puede ser suficiente para implementar los algoritmos de inteligencia artificial (IA). Este enfoque ha sido demostrado por Andreas Mangler, Director de Marketing Estratégico & Comunicaciones de Rutronik, junto a su equipo de ingeniería.
Sr. Mangler, usted y su equipo han desarrollado algoritmos que no requieren ni la nube – cloud ni un PC de elevado rendimiento, sino un microcontrolador. ¿Por qué?
Andreas Mangler: Observamos un movimiento claro en muchas aplicaciones industriales que abandonan el tener que analizar y evaluar datos externamente por medio de un proveedor de servicio (cloud analytics) o un PC industrial descentralizado (edge analytics) en favor de tenerlo todo implementado en un entorno separado y protegido como un sistema embebido basado en MCU (embedded analytics).
Y todo esto con el cifrado de hardware apropiado.
La protección IP y la capacidad de tiempo real del sistema se convierten en el centro de decisiones que respalda la analítica embebida, en particular la protección de los datos sin procesar, los algoritmos usados y sus series secuenciales con la intención de obtener finalmente la información deseada de los macrodatos (big data).
Y, además, los sistemas de analítica embebida se suelen basar en modelos matemáticos, patrones y funciones con los que se realiza una comparación de objetivo / actual usando los datos ya aprendidos y los datos medidos.
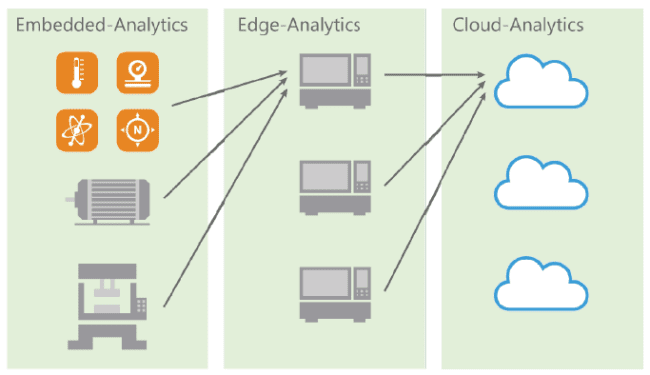
Por lo tanto, muchas tareas no sólo conllevan compartir patrones, que no necesariamente sólo se encuentran disponibles en el procesamiento de imagen o datos gráficos, sino también el proceso de una gran cantidad de datos de sensor con diversas variables físicas, que se suelen procesar de manera sincrónica: la palabra clave aquí es fusión de sensores.
Una solución de analítica embebida resulta indispensable, especialmente en sistemas de seguridad relevante o donde se requiere seguridad funcional en tiempo real y hay que tomar decisiones casi ad-hoc en el rango de los microsegundos o nanosegundos.
Una medida, por ejemplo, es el uso de filtros estocásticos, que se pueden soportar con la organización de memoria del MCU. Otra opción es la utilización de filtros IIR en sustitución de filtrado FIR orientado a los bloques como los filtros digitales, teniendo en cuenta el retardo de grupo diferente y la respuesta transitoria de las varias topologías de filtro.
Esto suena bastante sencillo, pero probablemente no lo sea. En un escenario real, ¿cómo se puede procesar esta grandísima cantidad de datos y algoritmos en un microcontrolador pequeño?
El problema de la fusión de sensores se describe muy bien por la palabra de moda VUCA, a saber: Volatility, Uncertainty, Complexity and Ambiguity (Volatilidad, Incertidumbre, Complejidad y Ambigüedad). La volatilidad aumenta porque el sistema está cambiando constantemente en términos de datos, dinámica, velocidad y límites. Las incertidumbres existen, por ejemplo, debido al ruido y a eventos imprevisibles. Además, los sistemas suelen ser complejos y hay ambigüedades, ya que algunos aspectos pueden tener diferentes causas. El objetivo es evaluar esta información “oculta” con la misión de proporcionar la mejor descripción del sistema. Los datos ya se pueden reducir mediante la estimación previa del estado actual.
Por ejemplo, un sistema de control de calor para un calentador de gas que tiene que llevar a cabo un análisis de CO2 podría determinar en paralelo la temperatura exterior exacta. De este modo, cuando se use en Noruega, el calentador puede tener en cuenta una temperatura de invierno de -30 °C al calcular el valor medido. En el sur de España, por el contrario, esta temperatura es extremadamente improbable o totalmente surrealista, en invierno. Por consiguiente, los datos del sensor de localización GPS o de la logística del fabricante del calentador determinan la cantidad de datos a evaluar.
La fórmula es: reducción de datos más algoritmos lean que se combinan correctamente. Esto requiere cuatro pasos: En primer lugar, la planificación del despliegue del sensor, a saber, dónde y cuántos sensores y de qué tipo se necesitan. El segundo paso concierne a la selección de datos y hay que responder a la siguiente pregunta: qué datos se requieren actualmente para detectar las anomalías. Así es como el big data se convierte en “datos inteligentes”. Ante todo, el “truco” es seleccionar tantos datos como necesitemos y a la vez el menor número posible, manteniendo la elección de los datos adecuados. En tercer lugar, hay que seleccionar los algoritmos para el filtrado previo. Los parámetros requeridos para el análisis se extraen en el cuarto paso. Todas las fases se tienen que adaptar al sistema y al problema actual. Además, se debe tener en consideración el problema básico del procesamiento de datos sincronizado en la fusión de sensores.
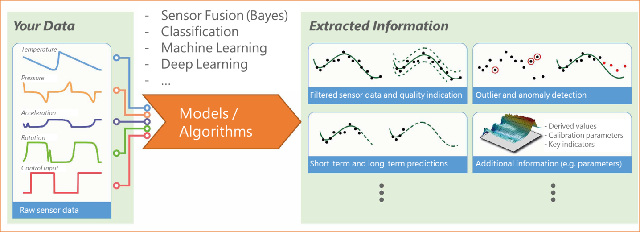
¿Cómo se puede implementar esto en la MCU?
En realidad, el sistema físico y los posibles estados se tienen en cuenta y se describen para este propósito. Esto se traduce posteriormente en una valoración del estado. Estos tipos de modelo se pueden definir con antelación en el laboratorio y almacenar en la tabla de consulta del microcontrolador. Entonces, los datos de los sensores se pueden comparar con el modelo y los valores atípicos se pueden identificar como una anomalía. Esto implica una menor necesidad de puntos de medida y, por ende, ahorra espacio de almacenamiento.
¿Puede explicar esto usando un ejemplo práctico?
Por supuesto; una aplicación típica sería un depósito de agua caliente inteligente conectado a un sistema fotovoltaico. Comenzamos con la planificación del despliegue de los sensores y especificamos la necesidad de algunos sensores de temperatura y de presión y aceleración.
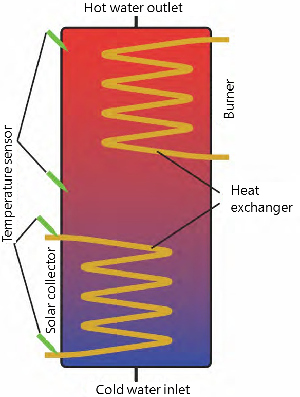
Ahora hay que evaluar el estado: como sé que, por ejemplo, la temperatura en el colector solar en estos componentes sólo oscila entre -20 a +50 °C, se puede omitir cualquier dato fuera de este rango. Desde un punto de vista puramente físico, el agua en el tanque no puede subir 30 °C de un minuto para otro y, como resultado, también es posible limitar el comportamiento dinámico en el rango de tiempo o frecuencia. Además, una diferencia de temperatura de un grado no afecta al sistema.
Por lo tanto, los datos se pueden analizar con un nivel de precisión de un grado.
El siguiente paso es identificar los datos relevantes para la tarea, por ejemplo, proteger ante el sobrecalentamiento. En este aspecto, la temperatura de los colectores solares, la entrada de agua fría y caliente, el intercambiador de calor y el quemador tienen un papel protagonista. Sus datos se deben filtrar desde la fusión de sensores. No hay que incluir nada más en el análisis. Esto supone que es primordial identificar el parámetro que influye en todo mi sistema.
Los datos seleccionados y filtrados ya están disponibles. ¿Cuál es el siguiente paso?
Ciertos patrones y anomalías se pueden detectar a través de filtros estadísticos, por ejemplo – y resultan aspectos interesantes para poder detectar el sobrecalentamiento en una primera fase de nuestro ejemplo. Al filtrar las anomalías, puedo limitar su análisis de datos.
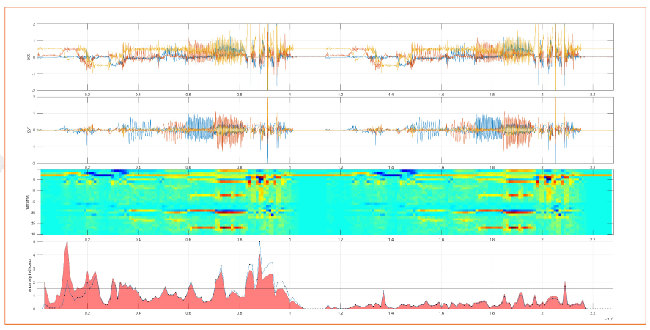
Con la intención de describir las anomalías, los valores extremos del sistema, como los valores máximo y mínimo y los puntos de inflexión, se tienen que explicar matemáticamente. Con cloud & edge analytics esto se consigue con ecuaciones diferenciales. Sin embargo, son demasiado costosos para la analítica embebida. Por ende, hemos sustituido la discusión de la curva matemática por un método de iteración de autoaprendizaje.
En principio, esto no parece ciencia de elevado nivel, sino las matemáticas aprendidas por los estudiantes de primer año en cada curso de ciencias básicas. Para la extracción y la consecuente visualización de los datos, resulta útil una representación bidimensional, ya que permite elegir una representación tridimensional para ubicar determinados parámetros identificados en el eje “z”. Esto se puede asemejar básicamente a un “mapa topológico” de los datos del sensor.
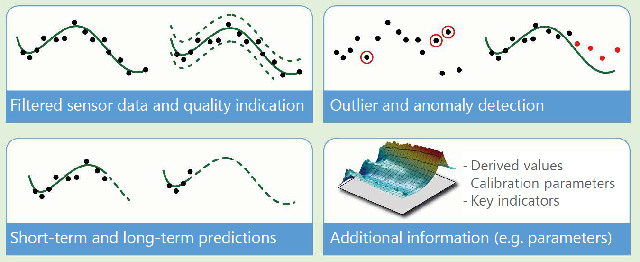
¿Cómo procedió con esto?
Elegimos un método de análisis tridimensional con la finalidad de hacer que los valores extremos sean reconocibles y, posteriormente, comparar los datos del modelo de sensor. Aquí ya se puede observar que algunos parámetros tienen poca o mínima influencia en las anomalías. Entonces, estos datos se pueden ignorar o filtrar en función de las necesidades.
Para poder explicar lo anteriormente descrito como “panorama topológico” (Imagen 5) matemáticamente, lo dividimos en menos de 100 subsegmentos y especificamos cada segmento con sólo 10 puntos de medida para la iteración, limitando el espacio de almacenamiento requerido desde el principio. Definimos la diferencia entre los datos del modelo y los datos de desviación como +/-1.5%. Estos son los límites de detección de las anomalías.
Entonces, implementamos un método de iteración de autoaprendizaje en un STM32 F4 de STMicroelectronics usando el denominado método diccionario. Esto implica programar unas preguntas iterativas que determinan qué funciones matemáticas del diccionario sirven para reemplazar una subsección de la función de sensor. En sólo tres o cuatro bucles de interrogación, llegamos al resultado que describe la curva característica del sensor con funciones matemáticas básicas – en otras palabras, un modelado exacto del sistema que identifica inmediatamente las anomalías. El “Diccionario de Función de Sensor” sólo contiene cinco funciones matemáticas básicas, como las funciones básicas radiales (RBF) o las funciones lineales.
El enfoque de autoaprendizaje reduce todavía más los segmentos y la cantidad de datos, lo que conlleva que se requieren 30 segmentos y, por ejemplo, 300 puntos de datos en lugar de 400. Todo se logra en tiempo real.
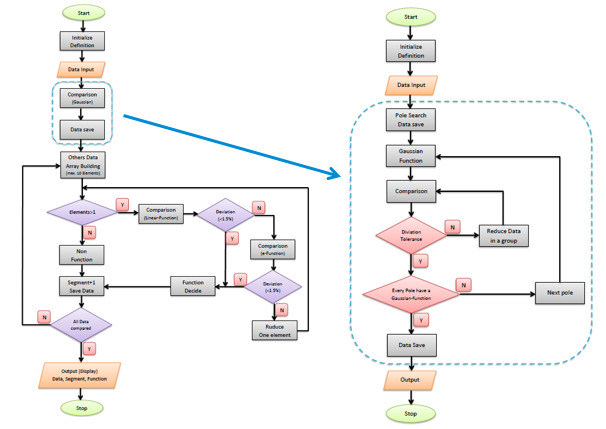
¿Esto se puede conseguir con cualquier microcontrolador?
En teoría sí, pero en la práctica no. Al procesar señales de varios sensores (fusión de sensores), la capacidad en tiempo real del MCU es el principal foco de atención. Se requiere una programación extremadamente eficiente para los procesos time-synchronous como, por ejemplo, los sensores MEMS con seis grados de libertad.
En lo que se refiere a las medidas time-critical, hemos descubierto que la programación en la capa de abstracción elevada (HAL – high abstraction layer) puede provocar errores de medición en el dominio de tiempo o que los cambios dinámicos de las anomalías a detectar eran insuficientes. La consecuencia fue la decisión de decantarse por una programación de bajo nivel.
Los requisitos de memoria dependen de la planificación previa del despliegue de sensores. Elegimos el STM32, ya que los periféricos analógicos y digitales combinados con la respuesta directa permiten una programación basada en ensamblador, con el objetivo de implementar la fusión de sensor con la RAM y la ROM existentes.
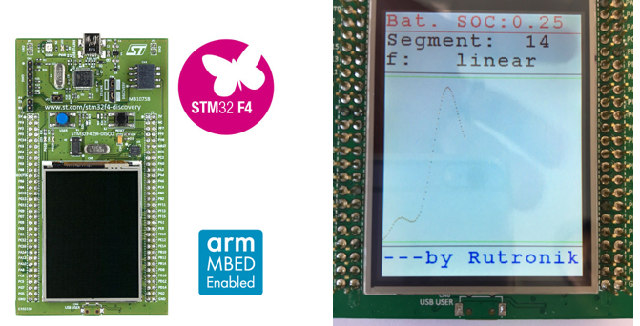
¿Este proceso de aprendizaje automático se dirige ahora a una aplicación específica?
No, los algoritmos de autoaprendizaje nos permiten “cartografiar” un sistema no lineal de todos los tipos de sensor y las fusiones de sensores. Además, cumple todos los requisitos de la analítica embebida: opera offline, esto es, sin una nube, en sistemas en tiempo real embebidos, se ejecuta en un MCU ARM estándar, y es robusto y escalable.
¿Cuál es mayor obstáculo durante la fase de desarrollo?
Se demanda un know-how completo en varias disciplinas y, en consecuencia, se requiere un equipo de expertos. Al seleccionar los parámetros y los patrones a compartir o determinar anomalías, hay que conocer totalmente el sistema físico. También se necesita un amplio conocimiento de todos los tipos de sensores y cómo trabajan para poder elegir los algoritmos matemáticos y de aprendizaje automático más apropiados. Disponemos de la gran ventaja de tener especialistas en sensores, soluciones analógicas y MCU en nuestro grupo. Además, nos beneficiamos de investigaciones anteriores llevadas a cabo por universidades asociadas y nuestra red de especialistas de hardware y software de terceras compañías como, por ejemplo, Knowtion, empresa dedicada a la fusión de sensores y el análisis de datos automático.
Podemos resumir este desarrollo de prueba de concepto de RUTRONIK de la siguiente manera: la inteligencia artificial y el aprendizaje automático a nivel de MCU embebido no son sólo una tarea de software. Resulta absolutamente necesario tener un conocimiento físico y electroquímico completo de los sensores y cómo funcionan con respecto a las anomalías de proceso para poder implementar un mantenimiento predictivo. Los recursos de ingeniería de RUTRONIK requeridos se encuentran disponibles para nuestros clientes y aportan el soporte necesario para seleccionar productos perfectamente coordinados.

: cómo funciona y por qué es esencial en electrónica")


: cómo funciona y por qué es esencial en electrónica")




.){kind=link}